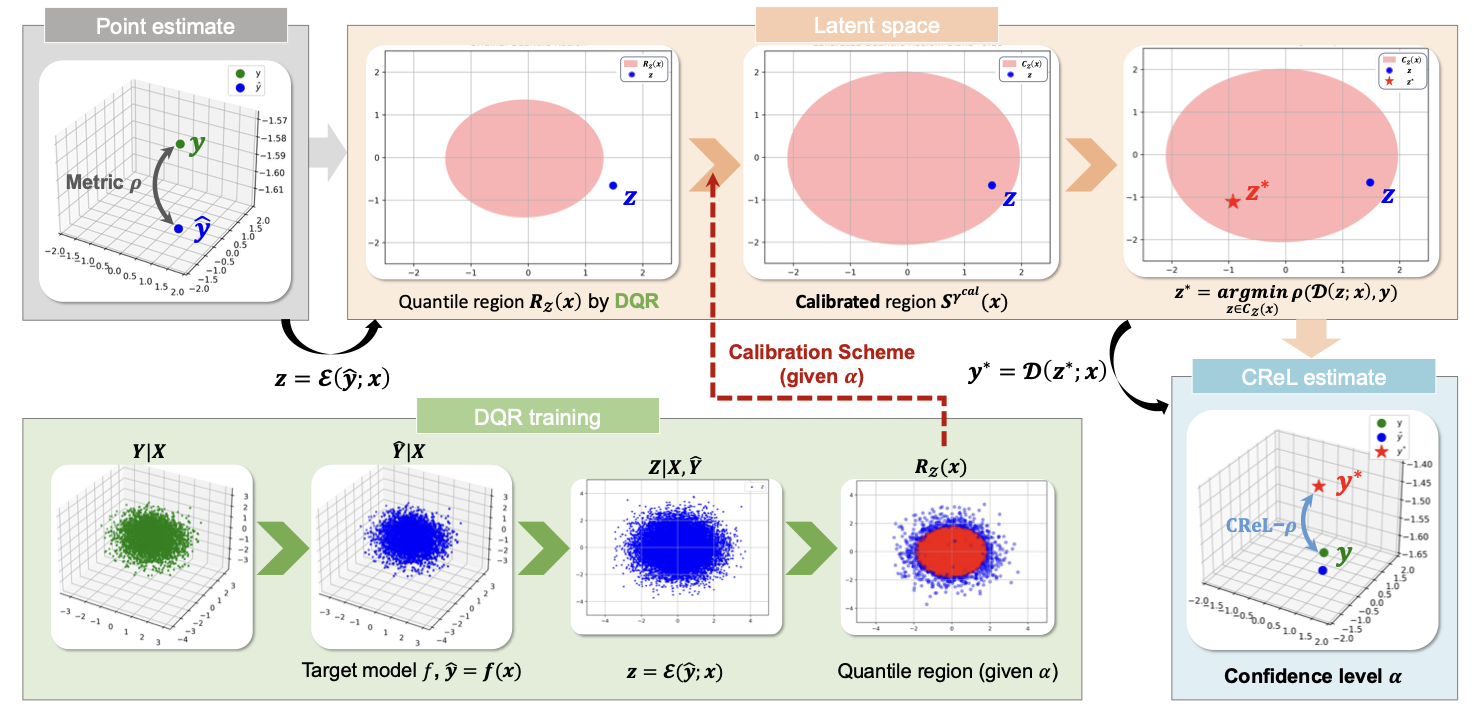
Conditional generative models have recently achieved remarkable success in various applications. However, a suitable metric for evaluating the reliability of these models, which takes into account their inherent uncertainty, is still lacking. Existing metrics, which typically assess a single output, may fail to capture the variability or potential risks in generation. In this paper, we propose a novel evaluation metric called reliability score based on conformal prediction, which measures the worst-case performance within the prediction set at a pre-specified confidence level. However, computing this score is challenging due to the high-dimensional nature of the output space and the nonconvexity of both the metric function and the prediction set.
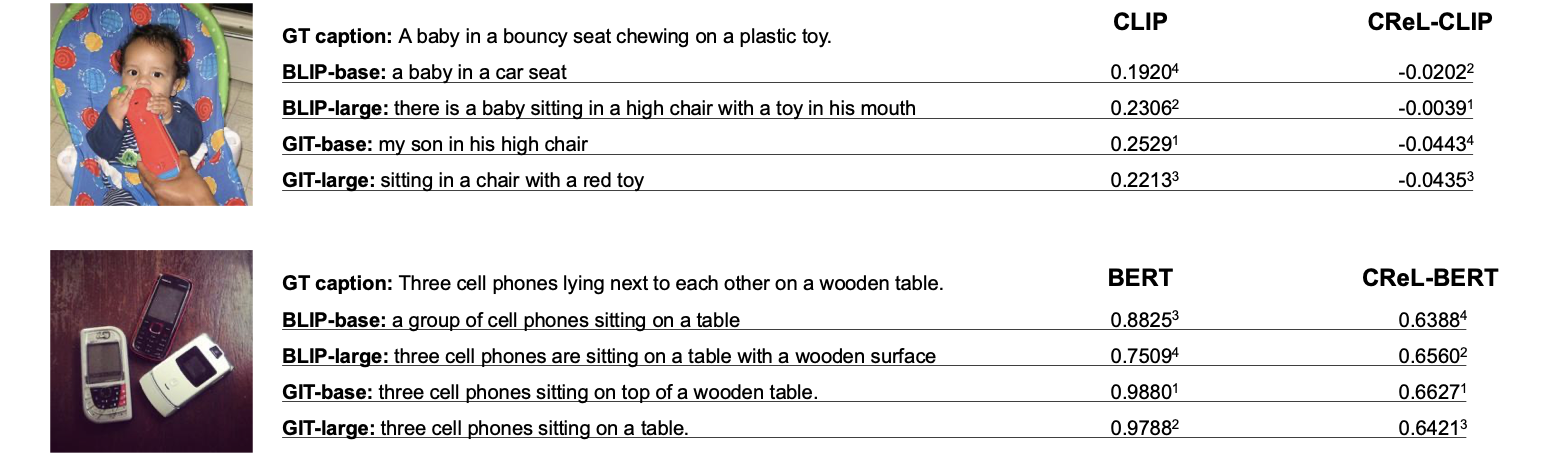
To efficiently compute this score, we introduce Conformal ReLiability (CReL), a framework that can (i) construct the prediction set with desired coverage; and (ii) accurately optimize the reliability score within the constructed prediction set. We provide theoretical results on coverage and demonstrate empirically that our method produces more informative prediction sets than existing approaches. Experiments on synthetic data and the image-to-text and text-to-image tasks further demonstrate the interpretability of our new metric, and the validity and effectiveness of our computational framework.